Data Versioning Your Processed Data
Does your team or company track the versions of your processed data? If not, maybe one should consider the added value of data versioning. When I use the term "data versioning", what I mean is tracking how your data such as an entity has changed over time. For example, with a data versioning process in place, changes to customers' primary addresses can be tracked. So what are some benefits of data versioning? The following are some of the key benefits of using a customer entity as an example.
Analytics for internal use. For example, if you were tracking your customer's addresses, you might be able to see how often customers change their addresses or where they are moving to.
Analytics for external use. For example, if you maintain a lot of data for customers, you may be able to provide retrospective analytics to your customer as a service.
Debugging. For example, if you have an ETL process that runs on a routine basis, but there were some errors in your processed data, you can check your data versioning to pinpoint when the errors started happening.
Speed-up Product Development. For example, your product team can learn more about how customers evolved over time without diving into the raw unprocessed data.
Possible Ways of Implementing Data Versioning
Off-the-shelf solution. One could use an off-the-shelf solution such as the python-based SQLAlchemy-Continuum. The upside of using such a solution is the speed of implementation. If you are already using SQLAlchemy, then the additional engineering hours needed are not high. The downside is that versioning only takes place within the SQLAlchemy based ETL process.
Custom-built Solution. With a custom-built solution, you can better integrate data versioning into your existing ETL or data pipelines. Of course, this will take more engineering hours than an off-the-shelf solution, but you gain control of where and how to integrate versioning.
Integration Examples
I will go over some high-level examples on how we can integrate versioning into your data pipelines. In our example, we will use the idea of a customer entity discussed above. We will assume a customer table already exists. And we will maintain a versioning table for this customer data. This versioning table will a summary of changes for all the customers. In these examples, we will represent the data pipeline as an Airflow DAG. In this DAG,Fig 1, there is a task to ingest the data, transform the data and a task to load the data into the tables.
Fig 1.
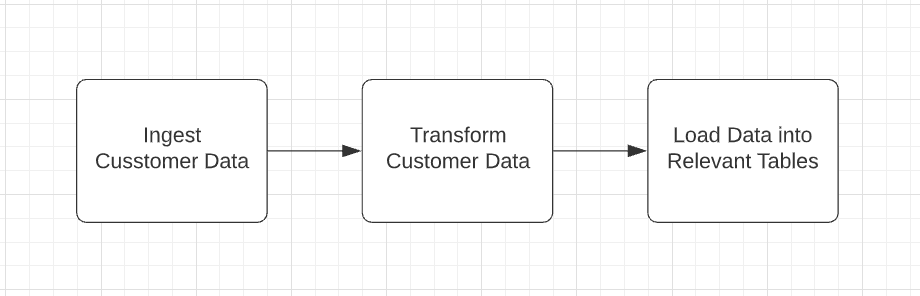
Example 1
The most straightforward approach is to add a data versioning step at the end of your ETL process. For example, if you use Airflow, this could be the last or one of the later tasks in your DAG.
Fig 2
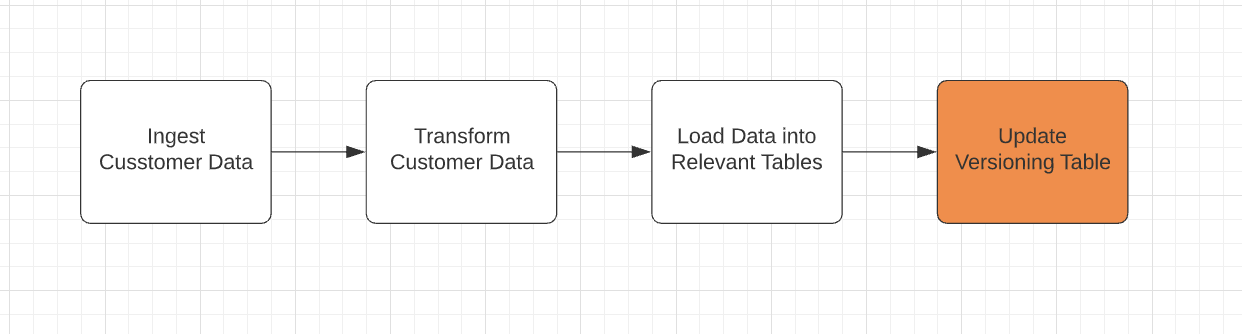
In this step, you will have a task that checks for changes in the newly processed data. The task will compare the data to the last iteration of the processed data. If there are changes, then insert a new version into a table that keeps track of all the different versions of your data. You can do this with a simple SQL statement to check for column changes. If there are changes, you insert the updated entity into the versioning table. So for example, if Joe Smith's address changed from 456 Broadway Blvd, Austin, TX to 103 Hamilton St, Austin, TX on 2019-02-15, then the last step will check the previous version of the entity in the versioning table and insert a new record to indicate the change. One could also add a start and end date columns to indicate when that record was active. Fig 3 below shows you how a versioning table could look like using our customer example.
Fig 3

Example 2
Another approach would be to create a separate pipeline or DAG for versioning that utilizes the same logic as the ETL process. This DAG will run in parallel to the regular ETL DAG. See Fig 4.
Fig 4
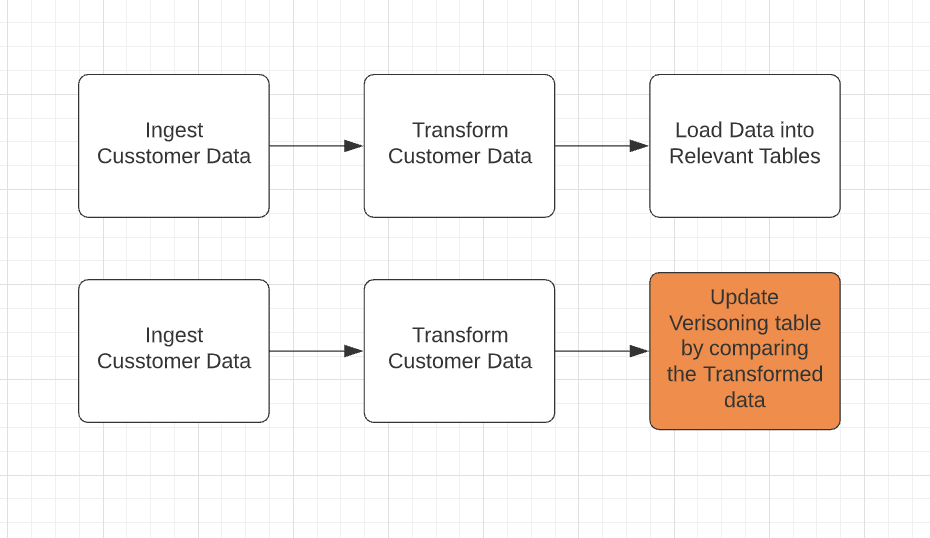
This process will be more resource intensive, but will allow your pipelines to stay independent. If your versioning pipeline fails, it will not affect your regular ETL process. In the first example, if the last versioning task gets stuck on retries, it may block your DAG from running its next scheduled run.